[OS] 2-2. System Structure & Program Execution 2
- IT/OS
- 2020. 12. 16.
1. 동기식 입출력과 비동기식 입출력

⇒ IO에서의 synchronous라고 하는 것은 IO까지 가서 결과를 보고 오는 것을 보통 동기식 입출력이라고 함.
⇒ 동기식 입출력은 I/O 요청 후 I/O장치로부터 작업이 끝난 다음에야 사용자 프로그램이 다음 일을 함. 비동기식 입출력은 I/O장치에 무언가를 요청한 다음 (결과를 기다리지 않고) 바로 다시 CPU제어권을 얻어서 일을 수행.
⇒ IO장치에 여럿이 동시에 접근할 수 있는데 예를들어, A는 이 IO장치에 갖다 쓰고(synchronous write), B는 읽어오고(synchronous read). 이 때, A, B 모두 읽고 쓰는 것 확인까지 한 상태
⇒ IO 장치에 가지 않고(확인하지 않고) 다음 일을 수행하는 것은 asynchronous(비동기식 입출력)

Synchronous IO
⇒ user 영역과 kernel 영역. IO는 커널을 통해서만 가능. 사용자 프로그램이 IO 요청을 OS 커널에게 하게되면 그 IO장치에 맞는 device driver를 거치고 실제 하드웨어를 통해 IO를 읽거나 쓰는 작업 수행.
⇒ IO는 꽤 오래 걸리는 작업. 시간이 흘러 IO 결과 도착(사용자는 기다림). 이걸 보고나서야 사용자는 그 다음 작업을 수행.
⇒ IO 디바이스 컨트롤러가 IO의 작업이 끝났다는 것을 인터럽트로 알려줌
ex) read : 어떤 프로그램을 짤 때 디스크로부터 무언가를 읽어오는 작업이 필요. 보통은 해당 내용을 읽어 온 다음 그 다음 루틴이 수행.
ex) write : write 작업은 보통 Synchronous하게 할 필요가 없음. (중간에 어떤 값이 storage에 저장 된 것을 확인해야만 다음 작업을 수행할 수 있는 경우가 아니면 그냥 write작업 중 다른 작업을 하는게 보통)
⇒ 사용자 프로그램이 IO요청을 하게 되면 CPU를 가지고 있으면서 아무일도 하지 않고 기다리는 상황이 발생
⇒ 보통, Synchronous IO요청이 있으면 기다리는 동안 CPU를 다른 사용자 프로그램에게 전달
Asynchronous IO
⇒ 사용자가 IO 요청을 OS커널에게 함. IO작업이 진행 되는 동안 사용자는 그것을 기다리지 않고 IO작업 요청만 해놓고 CPU 제어권을 얻어서 다른 작업 수행.
⇒ IO 디바이스 컨트롤러가 IO의 작업이 끝났다는 것을 인터럽트로 알려줌
ex) read :어떤 프로그램을 짤 때 디스크로부터 무언가를 읽어오는 작업이 필요. 그러나 이 작업이 IO결과를 보지 않고 디스크의 읽어온 결과와는 상관없이 할 수 있는 작업이 있을 수 있음. 그렇다면 IO작업이 수행되는 동안 사용자 프로그램에서 다른 작업 수행 가능
ex) write : write 작업은 보통 Synchronous하게 할 필요가 없음. (중간에 어떤 값이 storage에 저장 된 것을 확인해야만 다음 작업을 수행할 수 있는 경우가 아니면 그냥 write작업 중 다른 작업을 하는게 보통)
2. DMA(Direct Memory Access)

⇒ 메모리에 접근할 수 있는 장치(원래는 CPU만이 메모리에 접근 가능)
⇒ 키보드를 한 번 두드릴 때 마다 인터럽트를 걸고 CPU는 매번 그것을 확인하여 메모리에 복사를 한다면 CPU가 방해를 너무 많이 당함
⇒ 장치 컨트롤러가 데이터의 한 블록을 이동시키는데 이 과정에서 DMA로 인해 CPU의 개입이 필요없게 된다. CPU에서는 데이터 이동이 완료되었다는 단 한 번의 인터럽트만 발생한다. 데이터가 전송되는 동안 CPU는 다른 작업을 수행할 수 있게 되어 효율성이 높아진다.
3. 입출력 명령어(Instruction)

⇒ CPU에서 실행할 수 있는 기계어(명령어)는 메모리에 접근하는 명령과 IO 장치에 접근하는 명령이 있음
⇒ 왼쪽 그림이 일반적 (메모리에 접근하는 명령과 IO 장치에 접근하는 명령이 별개)
* Memory Mapped I/O : (오른쪽 그림) 메모리 주소를 IO디바이스들에다가 맵핑시켜서 메모리에 접근하는 instruction을 통해 IO에 할 수도 있음.
4. 저장장치 계층 구조
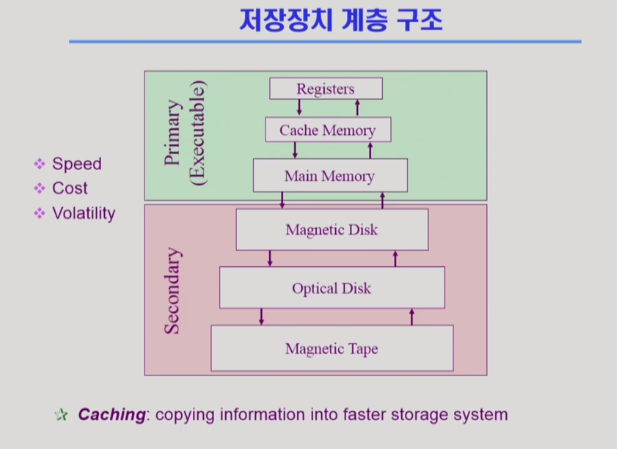
⇒ 맨 위에 CPU. CPU 안에 Registers, Cache Memory...
⇒ 위로 갈 수록 속도가 빠른 매체. 단위 공간 당 가격이 비쌈(용량이 적음)
⇒ 휘발성 or 비휘발성
* Secondary 계층의 하드디스크나 테입 같은 경우 전원이 나가도 내용이 사라지지 않음.
* Main Memory(DRAM), Cache Memory(SRAM), Registers 들은 전원이 나가면 내용이 사라짐(휘발성). (요 즘은 Main Memory도 비휘발성으로 나올 수 있는 새로운 반도체가 나오고 있지만 전통적으론 메인메모리 윗 단은 휘발성 하드디스크 아랫단은 비휘발성으로 분류)
⇒ CPU에서 직접 접근할 수 있는 메모리 스토리지 매체를 Primary(Executable, 실행가능하다)라고 부르고 CPU가 직접 접근해서 처리하지 못하는 매체를 Secondary라고도 부름
* CPU가 직접 접근하려면 Byte단위로 접근이 가능한 매체여야 함. DRAM 메모리(메인 메모리) 같은 경우 바 이트 단위로 주소를 매기기 때문에 접근(Executable)이 가능함.
* 하드디스크의 경우 바이트 단위 접근이 아님. 섹터 단위 접근. (Executable하지 않은 매체)
⇒ Caching
* 윗단, 아랫단. 윗단은 용량이 작음(모든 내용을 윗단에 담고있을 수는 없음). 아랫단은 속도가 느림.
* CPU가 Main Memory에 접근하는 데에 드는 시간을 완화하기 위해 Cache Memory 사용.
* Cache Memory는 메인 메모리보다 용량이 작음. 당장 필요한 것만 밑에서 위로 올려서 씀. 이것을 캐싱 이라고 부름.
* 보통 캐싱은 제 사용을 목적으로 함. 처음 요청(예를 들어 하드디스크 접근) 은 똑같이 시간(하드디스크까지 접근하는 시간)이 걸림.(밑에 까지 가야하니까) 일단 한 번 위로 올려 놓으면 캐시에 데이터를 읽어 왔기 때문에 빨리 데이터를 읽어 올 수 있음(밑에까지 가지 않음)
* 그런데 용량이 한정되어 있다보니 밑에서 모든것을 다 읽어 들이지는 못하고 새로운 것이 들어오면 기존에 있던것을 쫓아냄. (어떤것을 쫓아낼 것인가는 캐싱과 관련된 주요 이슈)
5. 프로그램의 실행

⇒ 프로그램은 보통 실행파일 형태로 하드디스크(File system)에 저장.
⇒ 그 실행파일을 실행시키면 메모리로 올라가서 프로세스가 됨.
⇒ 정확하게는 물리적인 메모리에 바로올라가는 것이 아니라 중간에 한 단계(Virtual memory)를 더 거침. (밑에 그림)

⇒ 어떤 프로그램을 실행시키면 그 프로그램만의 독자적인 주소공간이 형성됨(Address space)
⇒ A라는 프로그램을 실행시키면 0번지부터 시작하는 자신만의 주소공간이 생기고 B라는 프로그램을 실행시키면 0번지부터 시작하는 자신만의 주소공간이 만들어짐.
⇒ 이런 주소 공간은 code, data, stack과 같은 영역으로 구성됨.
* code : CPU에서 실행할 기계어(명령어) 코드를 담고 있음
* data : 변수와 같이 프로그램이 실행하는 자료 구조를 담고 있음
* stack : 코드는 함수구조로 구성되어 있기 때문에 함수를 호출하거나 리턴할 때 데이터를 쌓았다가 리턴하는 용도
⇒ 이런 각 프로그램의 독자적인 주소공간을 물리적엔 메모리에 올려서 실행을 시킴
⇒ 프로그램의 모든 주소공간을 Physical memory에 올리는 것이 아님. (메모리 낭비가 됨). 당장 필요한 부분만 올림. A라는 함수를 실행하고 있다면 그것에 해당하는 코드만 올려놓음(그림 참조)
⇒ 당장 필요한 코드만 올려놓으면 나머지는? 그렇지 않은 코드는 디스크에서 특별히 Swap area라는 곳에 내려놓게 됨.
⇒ 위 그림을 보면 하디드스크가 File system, Swap area 두 가지 형태로 있음. 용도가 다름. File system은 말 그대로 File system 용도. 전원이 나가더라도 내용유지가 됨. Swap area는 전원이 나가면 의미가 없는 데이터. 프로세스는 전원이 나가면 종료되고, 메모리 내용 또한 사라지기 때문.
⇒ Swap area는 메모리의 용량의 한계로 메모리의 연장공간의 용도로 사용되고 File system은 비휘발성의 용도로 전원이 나가도 내용을 유지시키기 위함. (용도가 다르기 때문에 관리방법도 다름. 뒷부분에서 설명)
⇒ Physical memory도 주소가 있음. 그렇다면 각 프로세스의 독자적인 주소가 Physical memory로 올라갈 때 이에 맞게 주소가 바뀌어야함.
⇒ 메모리 주소변환을 담당하는 계층이 있음(OS가 하는 것이 아니라 하드웨어의 지원을 받음. 뒷부분에서 설명!)
⇒ 운영체제의 커널 또한 하나의 프로그램이기 때문에 code, data, stack과 같은 형태의 주소공간으로 구성

1) OS 커널은 무슨일을 해야할까? → 코드 영역에 어떤 코드가 있어야 할까?
* 자원을 효율적으로 관리 → 관련된 코드
* 사용자에게 편리한 인터페이스를 제공 → 관련된 코드
* 운영체제는 CPU에 인터럽트가 들어올 때 제어권을 가짐 → 각각의 인터럽트마다 무슨일을 어떻게 처리해야하는지 → 관련된 코드
2) data
* 이 영역엔 OS가 사용하는 여러 자료구조들이 정의되어 있음.
* OS는 CPU나 메모리나 disk같은 하드웨어들을 직접 관리하고 통제. 이와 같은 하드웨어들을 관리하기 위해 각 하드웨어 종류마다 자료구조를 하나씩 만들어서 관리 (그림상 육면체(색깔)는 실제 하드웨어를 뜻하고 data영역 안에 들어있는 사각형(CPU, mem, disk)는 그런 하드웨어를 관리하기 위한 자료구조)
* OS는 현재 실행중인 프로그램(프로세스)들을 관리. 각 프로그램들이 CPU를 얼마나 썼는지, 다음엔 누구에게 CPU를 줘야하는 지에 관한 것들을 정하려면 또한 프로그램들마다의 자료구조가 필요. 그것을 PCB라고 부름. Process Control Block(⇒ 프로그램이 하나 돌아가면 그 프로그램을 관리하기 위한 자료구조가 OS커널에 하나씩 만들어지는데 그것이 PCB)
3) stack
* OS도 함수구조로 짜여져 있음.
* 함수를 호출하거나 리턴할 때 stack영역을 이용.
* 사용자 프로그램마다 커널 스택을 따로 둠(B프로그램의 스택, A프로그램의 스택 등)
6. 사용자 프로그램이 사용하는 함수

1) 커널 함수
* 커널함수는 내 프로그램 안에 들어 있는 함수가 아니라 OS안에 들어있는 함수.
* 내 프로그램에서 호출 가능(시스템 콜).
7. 프로그램의 실행 단계

A라는 프로그램의 시작~종료까지의 모습
1) A 프로그램을 실행시켰더니 먼저 사용자 정의 함수가 실행됨(User defined function call) ⇒ 여전히 user mode에서 실행 되고 있음
2) 그러다가 System call 함수를 만남 ⇒ 그 프로그램의 주소공간에 있는 코드가 아니라 OS 커널 주소공간에 있는 코드 실행. CPU는 커널로
3) System call이 끝나면 다시 A 프로그램으로 CPU가 넘어오고 그 프로그램의 주소공간에 있는 함수 실행. 라이브러리 함수를 실행하더라도 여전히 자신의 주소공간
4) 또 시스템 콜을 하면 다시 커널로
5) 끝
출처 : 반효경 교수님(이화여대) 강의
반효경 교수님의 강의를 들으며 정리한 것입니다.
'IT > OS' 카테고리의 다른 글
| [OS] 4. Process Management (0) | 2020.12.24 |
|---|---|
| [OS] 3-2. Process 2 (2) | 2020.12.24 |
| [OS] 3-1. Process 1 (0) | 2020.12.18 |
| [OS] 2-1. System Structure & Program Execution 1 (0) | 2020.12.15 |
| [OS] 1. Introduction to Operating Systems (0) | 2020.12.14 |